Вихідною для аналізу є матриця даних
розмірності  , i-й рядок якого характеризує i-е спостереження (об'єкт) за всіма k показниками
, i-й рядок якого характеризує i-е спостереження (об'єкт) за всіма k показниками  . Вихідні дані нормуються, навіщо обчислюються середні значення показників
. Вихідні дані нормуються, навіщо обчислюються середні значення показників  , а також значення стандартних відхилень
, а також значення стандартних відхилень  . Тоді матриця нормованих значень
. Тоді матриця нормованих значень

з елементами 
Розраховується матриця парних коефіцієнтів кореляції:

На головній діагоналі матриці розташовані одиничні елементи  .
.
Модель компонентного аналізу будується шляхом подання вихідних нормованих даних у вигляді лінійної комбінації основних компонентів:

де  - «Вага», тобто. факторне навантаження
- «Вага», тобто. факторне навантаження 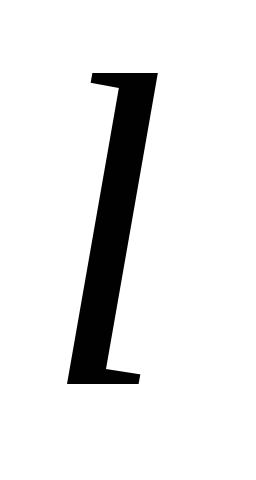 -ї головної компоненти на
-ї головної компоненти на  -ю змінну;
-ю змінну;
 -значення
-значення  -ї головної компоненти для
-ї головної компоненти для  -го спостереження (об'єкта), де
-го спостереження (об'єкта), де  .
.
У матричній формі модель має вигляд

тут  - матриця основних компонентів розмірності
- матриця основних компонентів розмірності  ,
,
 - матриця факторних навантажень тієї ж розмірності.
- матриця факторних навантажень тієї ж розмірності.
Матриця  описує
описує  спостережень у просторі
спостережень у просторі  Основні компоненти. При цьому елементи матриці
Основні компоненти. При цьому елементи матриці  нормовані, а головні компоненти не корельовані між собою. З цього виходить що
нормовані, а головні компоненти не корельовані між собою. З цього виходить що  , де
, де  - Поодинока матриця розмірності
- Поодинока матриця розмірності  .
.
Елемент  матриці
матриці  характеризує тісноту лінійного зв'язку між вихідною змінною
характеризує тісноту лінійного зв'язку між вихідною змінною  та головною компонентою
та головною компонентою  , отже, приймає значення
, отже, приймає значення  .
.
Кореляційна матриця  може бути виражена через матрицю факторних навантажень
може бути виражена через матрицю факторних навантажень  .
.
По головній діагоналі кореляційної матриці розташовуються одиниці і за аналогією з коваріаційною матрицею вони являють собою дисперсії використовуваних  -Ознак, але на відміну від останнього, внаслідок нормування, ці дисперсії рівні 1. Сумарна дисперсія всієї системи
-Ознак, але на відміну від останнього, внаслідок нормування, ці дисперсії рівні 1. Сумарна дисперсія всієї системи  -ознак у вибірковій сукупності обсягу
-ознак у вибірковій сукупності обсягу  дорівнює сумі цих одиниць, тобто. дорівнює сліду кореляційної матриці
дорівнює сумі цих одиниць, тобто. дорівнює сліду кореляційної матриці  .
.
Кореляційна матриць може бути перетворена на діагональну, тобто матрицю, всі значення якої, крім діагональних, дорівнюють нулю:
 ,
,
де  - діагональна матриця, на головній діагоналі якої знаходяться власні числа
- діагональна матриця, на головній діагоналі якої знаходяться власні числа  кореляційної матриці,
кореляційної матриці,  - матриця, стовпці якої – власні вектори кореляційної матриці
- матриця, стовпці якої – власні вектори кореляційної матриці  . Оскільки матриця R позитивно визначено, тобто. її головні мінори позитивні, то всі власні значення
. Оскільки матриця R позитивно визначено, тобто. її головні мінори позитивні, то всі власні значення  для будь-яких
для будь-яких  .
.
Власні значення  перебувають як коріння характеристичного рівняння
перебувають як коріння характеристичного рівняння

Власний вектор  , що відповідає власному значенню
, що відповідає власному значенню  кореляційної матриці
кореляційної матриці  , визначається як відмінне від нуля рішення рівняння
, визначається як відмінне від нуля рішення рівняння

Нормований власний вектор  дорівнює
дорівнює

Перетворення на нуль недіагональних членів означає, що ознаки стають незалежними один від одного (  при
при  ).
).
Сумарна дисперсія всієї системи  змінних у вибірковій сукупності залишається незмінною. Проте її значення перерозподіляється. Процедура знаходження значень цих дисперсій є знаходження власних значень
змінних у вибірковій сукупності залишається незмінною. Проте її значення перерозподіляється. Процедура знаходження значень цих дисперсій є знаходження власних значень  кореляційної матриці для кожного з
кореляційної матриці для кожного з  -Ознак. Сума цих значень
-Ознак. Сума цих значень  дорівнює сліду кореляційної матриці, тобто.
дорівнює сліду кореляційної матриці, тобто.  , тобто кількість змінних. Ці власні значення є величини дисперсії ознак
, тобто кількість змінних. Ці власні значення є величини дисперсії ознак  в умовах, якби ознаки були б незалежними одна від одної.
в умовах, якби ознаки були б незалежними одна від одної.
У методі основних компонентів спочатку за вихідними даними розраховується кореляційна матриця. Потім роблять її ортогональне перетворення і через це знаходять факторні навантаження  для всіх
для всіх 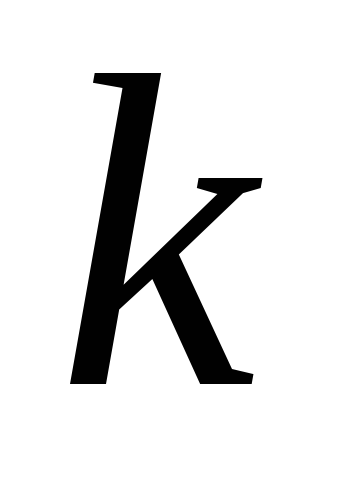 змінних та
змінних та  факторів (матрицю факторних навантажень), власні значення
факторів (матрицю факторних навантажень), власні значення  та визначають ваги факторів.
та визначають ваги факторів.
Матрицю факторних навантажень А можна визначити як 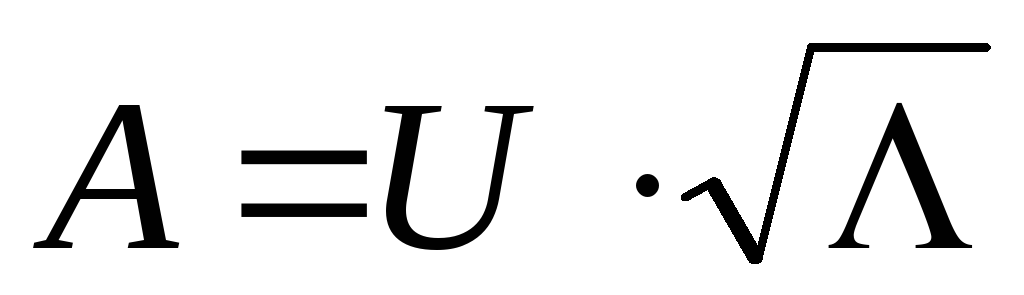 , а
, а  -й стовпець матриці А - як
-й стовпець матриці А - як  .
.
Вага факторів  або
або  відбиває частку загальної дисперсії, внесену цим чинником.
відбиває частку загальної дисперсії, внесену цим чинником.
Факторні навантаження змінюються від -1 до +1 є аналогом коефіцієнтів кореляції. У матриці факторних навантажень необхідно виділити значні та незначні навантаження за допомогою критерію Стьюдента  .
.
Сума квадратів навантажень  -го фактора у всіх
-го фактора у всіх  -ознаках дорівнює власному значенню даного фактора
-ознаках дорівнює власному значенню даного фактора  . Тоді
. Тоді  -вклад i-ої змінної у % у формуванні j-го фактора.
-вклад i-ої змінної у % у формуванні j-го фактора.
Сума квадратів всіх факторних навантажень по рядку дорівнює одиниці, повної дисперсії однієї змінної, а всіх факторів по всіх змінних дорівнює сумарній дисперсії (тобто сліду або порядку кореляційної матриці, або сумі її власних значень)  .
.
У загальному вигляді факторна структура i-го ознаки представляється у формі  , До якої включаються лише значні навантаження. Використовуючи матрицю факторних навантажень, можна обчислити значення всіх факторів для кожного спостереження вихідної вибіркової сукупності за формулою:
, До якої включаються лише значні навантаження. Використовуючи матрицю факторних навантажень, можна обчислити значення всіх факторів для кожного спостереження вихідної вибіркової сукупності за формулою:
 ,
,
де  - Значення j-ого фактора у t-ого спостереження,
- Значення j-ого фактора у t-ого спостереження,  -стандартизоване значення i-ого ознаки у t-ого спостереження вихідної вибірки;
-стандартизоване значення i-ого ознаки у t-ого спостереження вихідної вибірки;  -факторне навантаження,
-факторне навантаження,  -Власне значення, що відповідає фактору j. Ці обчислені значення
-Власне значення, що відповідає фактору j. Ці обчислені значення  широко використовуються для графічного уявлення результатів факторного аналізу.
широко використовуються для графічного уявлення результатів факторного аналізу.
По матриці факторних навантажень може бути відновлена кореляційна матриця:  .
.
Частина дисперсії змінної, яка пояснюється головними компонентами, називається спільністю
 ,
,
де  - Номер змінної, а
- Номер змінної, а  -Номер головної компоненти. Відновлені тільки по головним компонентам коефіцієнти кореляції будуть меншими за вихідні за абсолютною величиною, а на діагоналі будуть не 1, а величини спільностей.
-Номер головної компоненти. Відновлені тільки по головним компонентам коефіцієнти кореляції будуть меншими за вихідні за абсолютною величиною, а на діагоналі будуть не 1, а величини спільностей.
Питомий внесок  -ї головної компоненти визначається за формулою
-ї головної компоненти визначається за формулою
 .
.
Сумарний внесок врахованих  головних компонент визначається з виразу
головних компонент визначається з виразу
 .
.
Зазвичай для аналізу використовують 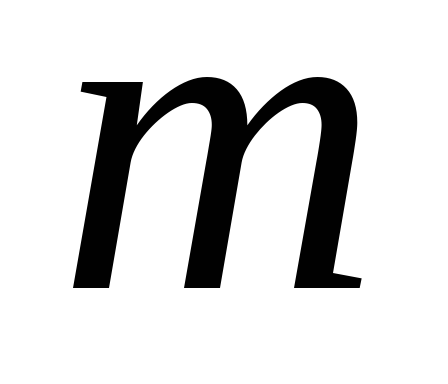 перших головних компонентів, вклад яких у сумарну дисперсію перевищує 60-70%.
перших головних компонентів, вклад яких у сумарну дисперсію перевищує 60-70%.
Матриця факторних навантажень А використовується для інтерпретації головних компонентів, причому зазвичай розглядаються ті значення, які перевищують 0,5.
Значення основних компонентів задаються матрицею

У цій статті я хотів би розповісти про те, як саме працює метод аналізу головних компонент (PCA – principal component analysis) з точки зору інтуїції, що стоїть за її математичним апаратом. Найбільш просто, але докладно.
Математика взагалі дуже гарна та витончена наука, але часом її краса ховається за купою шарів абстракції. Показати цю красу найкраще на простих прикладах, які, так би мовити, можна покрутити, пограти і помацати, тому що врешті-решт все виявляється набагато простіше, ніж здається на перший погляд найголовніше зрозуміти і уявити.
В аналізі даних, як і в будь-якому іншому аналізі, часом буває незайвим створити спрощену модель, що максимально точно описує реальний стан справ. Часто буває так, що ознаки досить сильно залежать одна від одної та їх одночасна наявність надмірно.
Наприклад, витрата палива в нас вимірюється в літрах на 100 км, а в США в милях на галон. На перший погляд, величини різні, але насправді вони залежать один від одного. У милі 1600км, а галоні 3.8л. Одна ознака строго залежить від іншої, знаючи одну, знаємо й іншу.
Але набагато частіше буває так, що ознаки залежать одна від одної не так строго і (що важливо!) не так очевидно. Об'єм двигуна в цілому позитивно впливає на розгін до 100 км/год, але це не завжди. А ще може виявитися, що з урахуванням не видимих на перший погляд факторів (типу поліпшення якості палива, використання легших матеріалів та інших сучасних досягнень) рік автомобіля не сильно, але теж впливає на його розгін.
Знаючи залежності та їх силу, ми можемо висловити кілька ознак через одну, злити докупи, так би мовити, і працювати вже з більш простою моделлю. Звичайно, уникнути втрат інформації, швидше за все, не вдасться, але мінімізувати її нам допоможе якраз метод PCA.
Висловлюючись суворіше, даний метод апроксимує n-розмірну хмару спостережень до еліпсоїда (теж n-вимірного), півосі якого і будуть майбутніми головними компонентами. І за проекції такі осі (зниженні розмірності) зберігається найбільше інформації.
Крок 1. Підготовка даних
Тут для простоти прикладу я не братиму реальні навчальні датасети на десятки ознак і сотні спостережень, а зроблю свій максимально простий іграшковий приклад. 2 ознаки та 10 спостережень буде цілком достатньо для опису того, що, а головне – навіщо, відбувається у надрах алгоритму.
Згенеруємо вибірку:

X = np.arange(1,11) y = 2 * x + np.random.randn(10)*2 X = np.vstack((x,y)) print X OUT: [[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. ] [2.73446908 4.35122722 7.21132988 11.24872601 9.58103444 12.09865079 12.7 03911 18.0998018 ]]
У цій вибірці у нас є дві ознаки, що сильно корелюють один з одним. За допомогою алгоритму PCA ми зможемо легко знайти ознаку-комбінацію і, ціною частини інформації, висловити обидві ці ознаки одним новим. Отже, розбираймося!
Для початку трохи статистики. Згадаємо, що з опису випадкової величини використовуються моменти. Потрібні нам – матюки. очікування та дисперсія. Можна сміливо сказати, що мат. очікування - це "центр тяжкості" величини, а дисперсія - це її "розміри". Грубо кажучи, матюки. очікування задає становище випадкової величини, а дисперсія – її розмір.
Сам процес проектування на вектор ніяк не впливає на значення середніх, тому що для мінімізації втрат інформації наш вектор має проходити через центр нашої вибірки. Тому немає нічого страшного, якщо ми відцентруємо нашу вибірку – лінійно зрушимо її так, щоб середні значення ознак дорівнювали 0. Це дуже спростить наші подальші обчислення (хоча, варто відзначити, що можна обійтися і без центрування).
Оператор, зворотний зсуву дорівнюватиме вектору початкових середніх значень – він знадобиться відновлення вибірки у вихідної розмірності.

Xcentered = (X - x.mean(), X - y.mean()) m = (x.mean(), y.mean()) print Xcentered print "Mean vector: ", m OUT: (array([ -4.5, -3.5, -2.5, -1.5, -0.5, 0.5, 1.5, 2.5, 3.5, 4.5]), array([-8.44644233, -8.32845585, -4.93314426, -3.16,3.5, 3.5, 3.5, 4.5. 3394, 1.86599939, 7.00558491, 4.21440647, 9.59501658])) Mean vector: (5.5, 10.314393916)
Дисперсія ж залежить від порядків значень випадкової величини, тобто. чутлива до масштабування. Тому якщо одиниці виміру ознак сильно відрізняються своїми порядками, рекомендується стандартизувати їх. У нашому випадку значення не сильно відрізняються в порядках, так що для простоти прикладу ми не виконуватимемо цю операцію.
Крок 2. Коварійна матриця
У випадку з багатовимірною випадковою величиною (випадковим вектором) положення центру так само буде мат. очікуваннями її проекцій на осі. А ось для опису її форми вже недостатньо тільки її дисперсій по осях. Подивіться ці графіки, в усіх трьох випадкових величин однакові мат.ожидания і дисперсії, які проекції на осі загалом виявляться однакові!

Для опису форми випадкового вектора необхідна матриця коваріації.
Це матриця, яка має (i,j)-Елемент є кореляцією ознак (Xi, Xj). Згадаймо формулу коваріації:
У нашому випадку вона спрощується, тому що E(X i) = E(X j) = 0:
Зауважимо, що коли X i = X j:
і це справедливо для будь-яких випадкових величин.
Таким чином, у нашій матриці по діагоналі будуть дисперсії ознак (т.к. i = j), а в інших осередках – коваріації відповідних пар ознак. А в силу симетричності підступу матриця теж буде симетрична.
Примітка:Коваріаційна матриця є узагальненням дисперсії у разі багатовимірних випадкових величин – вона як і визначає форму (розкид) випадкової величини, як і дисперсія.
І справді, дисперсія одновимірної випадкової величини – це матриця розміру 1x1, в якій її єдиний член заданий формулою Cov(X,X) = Var(X).
Отже, сформуємо коваріаційну матрицю Σ
для нашої вибірки. Для цього порахуємо дисперсії X i і X j, а також їхню коваріацію. Можна скористатися вищенаписаною формулою, але якщо ми озброїлися Python'ом, то гріх не скористатися функцією numpy.cov(X). Вона приймає на вхід список всіх ознак випадкової величини і повертає її матрицю коварації і де X – n-мірний випадковий вектор (n-кількість рядків). Функція відмінно підходить і для розрахунку незміщеної дисперсії, і для коваріації двох величин, і для складання матриці коваріації.
(Нагадаю, що в Python матриця представляється масивом-стовпцем масивів-рядків.)
Covmat = np.cov(Xcentered) print covmat, "n" print "Variance of X: ", np.cov(Xcentered) print "Variance of Y: ", np.cov(Xcentered) print "Covariance X and Y: " , np.cov(Xcentered) OUT: [[ 9.16666667 17.93002811] [ 17.93002811 37.26438587]] Variance of X: 9.16666666667 Variance of Y4 і 38 0281124
Крок 3. Власні вектори та значення (айгенпари)
О "кей, ми отримали матрицю, що описує форму нашої випадкової величини, з якої ми можемо отримати її розміри по x і y (тобто X 1 і X 2), а також зразкову форму на площині. Тепер треба знайти такий вектор (У нашому випадку тільки один), при якому максимізувався б розмір (дисперсія) проекції нашої вибірки на нього.
Примітка:Узагальнення дисперсії на вищі розмірності - підступна матриця, і ці два поняття еквівалентні. При проекції на вектор максимізується дисперсія проекції, при проекції простору великих порядків – вся її ковариационная матриця.
Отже, візьмемо одиничний вектор на який проектуватимемо наш випадковий вектор X. Тоді проекція на нього дорівнюватиме v T X. Дисперсія проекції на вектор буде відповідно дорівнює Var(v T X). Загалом у векторній формі (для центрованих величин) дисперсія виражається так:
Відповідно, дисперсія проекції:
Легко помітити, що дисперсія максимізується за максимального значення v T Σv. Тут нам допоможе ставлення Релея. Не вдаючись надто глибоко в математику, просто скажу, що відносини Релея мають спеціальний випадок для коваріаційних матриць:
Остання формула має бути знайома за темою розкладання матриці на власні вектори та значення. x є власним вектором, а - власним значенням. Кількість власних векторів та значень дорівнюють розміру матриці (і значення можуть повторюватися).
До речі, в англійській мові власні значення та вектори називаються eigenvaluesі eigenvectorsвідповідно.
Мені здається, це звучить набагато красивіше (і стисло), ніж наші терміни.
Таким чином, напрямок максимальної дисперсії у проекції завжди збігається з айгенвектором, що має максимальне власне значення, що дорівнює величині цієї дисперсії.
І це справедливо також для проекцій на більшу кількість вимірювань – дисперсія (коваріаційна матриця) проекції на m-мірний простір буде максимальною у напрямку m айгенвекторів, що мають максимальні власні значення.
Розмірність нашої вибірки дорівнює двом і кількість айгенвекторів у неї, відповідно, 2. Знайдемо їх.
У бібліотеці numpy реалізовано функцію numpy.linalg.eig(X), де X - Квадратна матриця. Вона повертає 2 масиви - масив айгензначень і масив айгенвекторів (вектори-стовпці). І вектори нормовані – їх довжина дорівнює 1. Саме те, що треба. Ці 2 вектори задають новий базис для вибірки, такий, що його осі збігаються з півосями апроксимуючого еліпса нашої вибірки.

На цьому графіку ми апроксимували нашу вибірку еліпсом з радіусами в 2 сигми (тобто він повинен містити в собі 95% всіх спостережень – що ми тут і спостерігаємо). Я інвертував більший вектор (функція eig(X) направляла його у зворотний бік) – нам важливий напрямок, а не орієнтація вектора.
Крок 4. Зниження розмірності (проекція)
Найбільший вектор має напрямок, схожий на лінію регресії і спроектувавши на нього нашу вибірку ми втратимо інформацію, порівнянну із сумою залишкових членів регресії (тільки відстань тепер евклідова, а не дельта по Y). У нашому випадку залежність між ознаками дуже сильна, тому втрата інформації буде мінімальною. «Ціна» проекції – дисперсія за меншим айгенвектором – як видно з попереднього графіка, дуже невелика.
Примітка:діагональні елементи ковариационной матриці демонструють дисперсії по початковому базису, та її власні значення – по новому (по основним компонентам).
Часто потрібно оцінити обсяг втраченої (і збереженої) інформації. Найзручніше уявити у відсотках. Ми беремо дисперсії по кожній осі і ділимо на загальну суму дисперсій по осях (тобто суму всіх власних чисел підступної матриці).
Таким чином, наш більший вектор описує 45.994/46.431*100% = 99.06%, а менший, відповідно, приблизно 0.94%. Відкинувши менший вектор та спроектувавши дані на більший, ми втратимо менше 1% інформації! Відмінний результат!
Примітка:Насправді, здебільшого, якщо сумарна втрата інформації становить трохи більше 10-20%, можна спокійно знижувати розмірність.
Для проведення проекції, як згадувалося раніше на кроці 3, треба провести операцію v T X (вектор повинен бути довжини 1). Або якщо у нас не один вектор, а гіперплощина, то замість вектора v T беремо матрицю базисних векторів V T . Отриманий вектор (або матриця) буде масивом проекцій спостережень.
V = (-vecs, -vecs) Xnew = dot (v, Xcentered) print Xnew OUT: [-9.56404107 -9.02021624 -5.52974822 -2.96481262 0.68933859 0.743433 .3212742 10.59672425]
dot(X,Y)- почленний твір (так ми перемножуємо вектори та матриці в Python)
Неважко помітити, що значення проекцій відповідають картині на попередньому графіку.
Крок 5. Відновлення даних
З проекцією зручно працювати, будувати на її основі гіпотези та розробляти моделі. Не завжди отримані основні компоненти матимуть явний, зрозумілий сторонній людині, сенс. Іноді корисно розкодувати, наприклад, виявлені викиди, щоб подивитися, що за ними стоять.
Це дуже просто. У нас є вся необхідна інформація, а саме координати базисних векторів у вихідному базисі (вектори, на які ми проектували) та вектор середніх (для скасування центрування). Візьмемо, наприклад, найбільше значення: 10.596 і розкодуємо його. Для цього помножимо його праворуч на транспонований вектор і додамо вектор середніх, або в загальному вигляді для всієї вибоки: X T v T +m
Xrestored = dot(Xnew,v) + m print "Restored: ", Xrestored print "Original: ", X[:,9] OUT: Restored: [ 10.13864361 19.84190935] Original: [ 10. 19.9094
Різниця невелика, але вона є. Адже втрачена інформація не відновлюється. Проте, якщо простота важливіша за точність, відновлене значення відмінно апроксимує вихідне.
Замість висновку – перевірка алгоритму
Отже, ми розібрали алгоритм, показали як він працює на іграшковому прикладі, тепер залишилося лише порівняти його з PCA, реалізованим у sklearn – адже будемо користуватися саме ним.
З sklearn.decomposition import PCA pca = PCA(n_components = 1) XPCAreduced = pca.fit_transform(transpose(X))
Параметр n_componentsвказує на кількість вимірювань, на які проводитиметься проекція, тобто до скільки вимірювань ми хочемо знизити наш датасет. Іншими словами - це n айгенвекторів з найбільшими власними числами. Перевіримо результат зниження розмірності:
Print "Our reduced X: n", Xnew print "Sklearn reduced X: n", XPCAreduced OUT: Our reduced X: [-9.56404106 -9.02021625 -5.52974822 -2.96481262 0.649 449 2 7.39307974 5.3212742 10.59672425] Sklearn reduced X: [[ -9.56404106 ] [-9.02021625] [-5.52974822] [-2.96481262] [0.68933859] [0.74406645] [2.33433492] [7.39307974] [7.2]
Ми повертали результат як матрицю векторних стовпців спостережень (це більш канонічний вигляд з точки зору лінійної алгебри), PCA в sklearn повертає вертикальний масив.
В принципі, це не критично, просто варто відзначити, що в лінійній алгебрі канонічно записувати матриці через вектор-стовпці, а в аналізі даних (та інших пов'язаних з БД областях) спостереження (транзакції, записи) зазвичай записуються рядками.
Перевіримо та інші параметри моделі – функція має ряд атрибутів, що дозволяють отримати доступ до проміжних змінних:
Вектор середніх: mean_
- Вектор(матриця) проекції: components_
- Дисперсії осей проекції (вибіркова): explained_variance_
- частка інформації (частка від загальної дисперсії): explained_variance_ratio_
Примітка: explained_variance_ показує вибірковудисперсію, тоді як функція cov() для побудови коварійної матриці розраховує незміщенідисперсії!
Порівняємо отримані нами значення зі значеннями бібліотечної функції.
Print "Mean vector: ", pca.mean_, m print "Projection: ", pca.components_, v print "Explained variance ratio: ", pca.explained_variance_ratio_, l/sum(l) OUT: Mean vector: [ 5.5 10.314393 (5.5, 10.314393916) Projection: [[0.43774316 0.89910006]] (0.43774316434772387, 0.89910006232167594) Explained varian5. 918 Explained variance ratio: [0.99058588] 0.990585881238
Єдина відмінність – у дисперсіях, але як ми вже згадували, ми використовували функцію cov(), яка використовує незміщену дисперсію, тоді як атрибут explained_variance_ повертає вибіркову. Вони відрізняються лише тим, що перша для отримання мат. очікування ділить на (n-1), а друга – на n. Легко перевірити, що 45.99 ∙ (10 – 1) / 10 = 41.39.
Усі інші значення збігаються, що означає, що наші алгоритми є еквівалентними. І насамкінець зауважу, що атрибути бібліотечного алгоритму мають меншу точність, оскільки він напевно оптимізований під швидкодію, або просто для зручності округляє значення (або в мене якісь глюки).
Примітка:бібліотечний метод автоматично проектує на осі, що максимізують дисперсію. Це не завжди раціонально. Наприклад, цьому малюнку неакуратне зниження розмірності призведе до того що, що класифікація стане неможлива. Проте проекція на менший вектор успішно знизить розмірність та збереже класифікатор.

Отже, ми розглянули принципи роботи алгоритму PCA та його реалізації у sklearn. Я сподіваюся, ця стаття була досить зрозумілою тим, хто тільки починає знайомство з аналізом даних, а також хоч трохи інформативною для тих, хто добре знає даний алгоритм. Інтуїтивне уявлення вкрай корисне для розуміння того, як працює метод, а розуміння дуже важливе для правильного налаштування обраної моделі. Дякую за увагу!
PS:Прохання не лаяти автора за можливі неточності. Автор сам у процесі знайомства з дата-аналізом і хоче допомогти таким же, як він у процесі освоєння цієї дивовижної галузі знань! Але конструктивна критика та різноманітний досвід усіляко вітаються!
ЗАСТОСУВАННЯ МЕТОДУ ГОЛОВНИХ КОМПОНЕНТ
ДЛЯ ОБРОБКИ БАГАТОМІРНИХ СТАТИСТИЧНИХ ДАНИХ
Розглянуто питання обробки багатовимірних статистичних даних рейтингової оцінки студентів на основі застосування методу основних компонентів.
Ключові слова: багатовимірний аналіз даних, зниження розмірності, метод основних компонентів, рейтинг.
Насправді часто доводиться стикатися з ситуацією, коли об'єкт дослідження характеризується безліччю різноманітних параметрів, кожен із яких вимірюється чи оцінюється. Аналіз отриманого в результаті дослідження кількох однотипних об'єктів масиву вихідних даних є практично нерозв'язним завданням. Тому досліднику необхідно проаналізувати зв'язки та взаємозалежності між вихідними параметрами, щоб відкинути частину з них або замінити їх меншим числом будь-яких функцій від них, зберігши при цьому по можливості всю укладену в них інформацію.
У зв'язку з цим постають завдання зниження розмірності, тобто переходу від вихідного масиву даних до істотно меншої кількості показників, відібраних з числа вихідних або отриманих шляхом деякого їх перетворення (з найменшою втратою інформації, що міститься у вихідному масиві), і класифікації - поділу аналізованої сукупності об'єктів на однорідні (у певному сенсі) групи. Якщо з великому числу різнотипних і стохастично взаємопов'язаних показників було отримано результати статистичного обстеження цілої сукупності об'єктів, то вирішення завдань класифікації та зниження розмірності слід використовувати інструментарій багатовимірного статистичного аналізу, зокрема метод головних компонент .
У статті пропонується методика застосування методу основних компонентів для обробки багатовимірних статистичних даних. Як приклад наводиться вирішення завдання статистичної обробки багатовимірних результатів рейтингової оцінки студентів.
1. Визначення та обчислення головних компонент..png" height="22 src="> ознак. В результаті отримуємо багатовимірні спостереження, кожне з яких можна представити у вигляді векторного спостереження
де https://pandia.ru/text/79/206/images/image005.png" height = "22 src = ">.
Отримані багатовимірні спостереження необхідно статистичною обробкою..png" height="22 src=">.png" height="22 src=">.png" width="132" height="25 src=">.png" width ="33" height="22 src="> допустимих перетворень досліджуваних ознак 0 style="border-collapse:collapse">

- Умова нормування; | ||
| - Умова ортогональності |

Отримані подібним перетворенням і являють собою головні компоненти. З них при подальшому аналізі виключають змінні з мінімальною дисперсією. , Т. е.. png width="131" height="22 src="> у перетворенні (2)..png" width="13" height="22 src="> цієї матриці рівні дисперсіям головних компонент .
Таким чином, першою головною компонентою називається така нормовано-центрована лінійна комбінація цих показників, яка серед усіх інших подібних комбінацій має найбільшу дисперсію. png width="12" – власний вектор матриці https://pandia.ru/text/79/206/images/image025.png" width="15" 22 src=">.png" width="80" "> називається така нормовано-центрована лінійна комбінація цих показників, яка не корелюється з https://pandia.ru/text/79/206/images/image013.png" width="80" height="23 src=">. png" width="80" height="23 src="> вимірюються в різних одиницях, то результати дослідження за допомогою головних компонент будуть істотно залежати від вибору масштабу та природи одиниць виміру , а отримані лінійні комбінації вихідних змінних буде важко інтерпретувати. У зв'язку з цим за різних одиниць вимірювання вихідних ознак DIV_ADBLOCK310">
https://pandia.ru/text/79/206/images/image030.png" width="17" height="22 src=">.png" width="56" height="23 src=">. Після такого перетворення проводять аналіз основних компонентів щодо величин https://pandia.ru/text/79/206/images/image033.png" , яка є одночасно кореляційною матрицею https://pandia.ru/text/79/206/images/image035.png" width="162" src="> на i- й вихідна ознака ..png" width="14" height="22 src=">.png" width="10" height="22 src="> дорівнює дисперсії v- й головної компоненти використовуються при змістовній інтерпретації головних компонент. png width="20" height="22 src=">.png" width="251" height="25 src=">
Для проведення розрахунків векторні спостереження агрегуємо у вибіркову матрицю, в якій рядки відповідають контрольованим ознакам, а стовпці – об'єктам дослідження. " height="67 src=">
Після центрування вихідних даних знаходимо вибіркову кореляційну матрицю за формулою
https://pandia.ru/text/79/206/images/image045.png" width="204" height="69 src=">
Діагональні елементи матриці width="206" height="68 src=">
Недіагональні елементи цієї матриці є вибірковими оцінками коефіцієнтів кореляції між відповідною парою ознак.
Складаємо характеристичне рівняння для матриці 0 "border-collapse:collapse">

Знаходимо все його коріння:
Тепер для знаходження компонент головних векторів підставляємо послідовно чисельні значення https://pandia.ru/text/79/206/images/image065.png" width="16" " height="24 src=">
Наприклад, при https://pandia.ru/text/79/206/images/image069.png" width="262" height="70 src=">
Очевидно, що отримана система рівнянь спільна через однорідність і невизначена, тобто має безліч рішень. Для знаходження єдиного рішення, що нас цікавить, скористаємося такими положеннями:
1. Для коріння системи може бути записано співвідношення
https://pandia.ru/text/79/206/images/image071.png" width="20" height="23 src="> – алгебраїчне доповнення j-го елемента будь-який i-й рядки матриці системи
2. Наявність умови нормування (2) забезпечує єдиність розв'язання системи рівнянь. власних векторів не відіграють істотної ролі, оскільки їх зміна не впливає на результат аналізу, вони можуть служити лише для індикації протилежних тенденцій на відповідній головній компоненті.
Таким чином, отримуємо власний вектор width="15"
https://pandia.ru/text/79/206/images/image024.png" width="12" height="22 src="> перевіряємо по рівності
https://pandia.ru/text/79/206/images/image076.png" width="503" height="22">
… … … … … … … … …
https://pandia.ru/text/79/206/images/image078.png" width="595" height="22 src=">
https://pandia.ru/text/79/206/images/image080.png" width="589" height="22 src=">
де https://pandia.ru/text/79/206/images/image082.png" width="16" height="22 src=">.png" width="23" height="22 src="> - Стандартизовані значення відповідних вихідних ознак.
Складаємо ортогональну матрицю лінійного перетворення.
Так як відповідно до властивостей головних компонентів сума дисперсій вихідних ознак дорівнює сумі дисперсій всіх головних компонентів, то з урахуванням того, що ми розглядали нормовані вихідні ознаки, можна оцінити, яку частину загальної мінливості вихідних ознак пояснює кожна з головних компонентів. Наприклад, для перших двох головних компонентів маємо:
|
|
Таким чином, відповідно до критерію інформативності, що використовується для головних компонентів, знайдених за кореляційною матрицею, сім перших головних компонентів пояснюють 88,97% загальної мінливості п'ятнадцяти вихідних ознак.
Використовуючи матрицю лінійного перетворення width="10" (для семи перших головних компонент):
https://pandia.ru/text/79/206/images/image090.png" width="16" height="22 src="> – число дипломів, отриманих у конкурсі наукових та дипломних робіт; .ru/text/79/206/images/image092.png" width="16" height="22 src=">.png" width="22" height="22 src=">.png" width=" 22" height="22 src=">.png" width="22" height="22 src="> – нагороди та призові місця, зайняті на регіональних, обласних та міських спортивних змаганнях.
3..png" width="16" height="22 src=">(кількість грамот за результатами участі в конкурсах наукових та дипломних робіт).
4..png" width="22" height="22 src=">(нагороди та призові місця, зайняті на вузівських змаганнях).
6. Шоста головна компонента позитивно корельована з показником DIV_ADBLOCK311">
4. Третій головний компонент – активність студентів у навчальному процесі.
5. Четверта та шоста компоненти – старанність студентів протягом весняного та осіннього семестрів відповідно.
6. П'ята головна компонента – ступінь участі у спортивних змаганнях університету.
Надалі для проведення всіх необхідних розрахунків при виділенні головних компонентів пропонується використовувати спеціалізовані статистичні програмні комплекси, наприклад STATISTICA, що суттєво полегшить процес аналізу.
Описаний у цій статті процес виділення головних компонентів на прикладі рейтингової оцінки студентів пропонується використовувати для атестації бакалаврів та магістрів.
СПИСОК ЛІТЕРАТУРИ
1. Прикладна статистика: Класифікація та зниження розмірності: довід. вид. / , ; за ред. . - М.: Фінанси та статистика, 1989. - 607 с.
2. Довідник з прикладної статистики: в 2 т.: [Пер. з англ.] / за ред. Еге. Ллойда, У. Ледермана, . - М.: Фінанси та статистика, 1990. - Т. 2. - 526 c.
3. Прикладна статистика. Основи економетрики. У 2 т. т.1. Теорія ймовірностей та прикладна статистика: навч. для вузів /, B. C. Мхітарян. – 2-ге вид., испр.– М: ЮНИТИ-ДАНА, 2001. – 656 з.
4. Афіфі, А. Статистичний аналіз: підхід з використанням ЕОМ: [Пер. з англ.] / А. Афіфі, С. Ейзен. - М.: Світ, 1982. - 488 с.
5. Дронов, статистичний аналіз: навч. допомога / . - Барна3. - 213 с.
6. Андерсон, Т. Введення в багатовимірний статистичний аналіз/Т. Андерсон; пров. з англ. [та ін.]; за ред. . - М.: Держ. вид-во фіз.-мат. літ., 1963. - 500 с.
7. Лоулі, Д. Факторний аналіз як статистичний метод / Д. Лоулі, А. Максвелл; пров. з англ. . - М.: Світ, 1967. - 144 с.
8. Дубров, статистичні методи: підручник /, . - М.: Фінанси та статистика, 2003. - 352 с.
9. Кендалл, М. Багатомірний статистичний аналіз та часові ряди / М. Кендалл, А. Стьюарт;пер. з англ. , ; за ред. , . - М.: Наука,1976. - 736 с.
10. Білоглазов, аналіз у завданнях кваліметрії освіти // Изв. РАН. Теорія та системи управління. - 2006. - №6. - С. 39 - 52.
Матеріал надійшов до редколегії 8.11.11.
Робота виконана в рамках реалізації федеральної цільової програми «Наукові та науково-педагогічні кадри інноваційної Росії» на 2009 – 2013 рр. (Державний договір № П770).
Метод основних компонентабо компонентний аналіз(Principal component analysis, PCA) - один із найважливіших методів в арсеналі зоолога або еколога. На жаль, у випадках, коли цілком доречним є застосування компонентного аналізу, часто застосовують кластерний аналіз.
Типова задача, для якої корисний компонентний аналіз, така: є безліч об'єктів, кожен з яких охарактеризований за певною (досить великою) кількістю ознак. Дослідника цікавлять закономірності, відображені у різноманітності цих об'єктів. У разі, коли є підстави припускати, що об'єкти розподілені по ієрархічно підпорядкованим групам, можна використовувати кластерний аналіз - метод класифікації(Розподіли по групах). Якщо немає підстав очікувати, що у різноманітності об'єктів відбито якусь ієрархію, логічно використовувати ординацію(Упорядковане розташування). Якщо кожен об'єкт охарактеризовано за досить великою кількістю ознак (принаймні - такою кількістю ознак, яку не виходить адекватно відобразити на одному графіку), оптимально розпочинати дослідження даних з аналізу основних компонентів. Справа в тому, що цей метод є одночасно методом зниження розмірності (кількості вимірів) даних.
Якщо група об'єктів, що розглядаються, охарактеризована значеннями однієї ознаки, для характеристики їх різноманітності можна використовувати гістограму (для безперервних ознак) або стовпчасту діаграму (для характеристики частот дискретної ознаки). Якщо об'єкти охарактеризовані двома ознаками, можна використовувати двовимірний графік розсіювання, якщо три - тривимірний. А якщо ознак багато? Можна спробувати на двовимірному графіку відобразити взаємне розташування об'єктів один щодо одного багатомірному просторі. Зазвичай таке зниження розмірності пов'язані з втратою інформації. З різних можливих способів такого відображення треба вибрати той, за якого втрата інформації буде мінімальною.
Пояснимо сказане на простому прикладі: переході від двовимірного простору до одномірного. Мінімальна кількість точок, що задає двовимірний простір (площина) – 3. На рис. 9.1.1 показано розташування трьох точок на площині. Координати цих точок легко читаються за малюнком. Як вибрати пряму, яка нестиме максимальну інформацію про взаєморозташування точок?
Мал. 9.1.1. Три крапки на площині, заданій двома ознаками. На яку пряму проектуватиметься максимальна дисперсія цих точок?
Розглянемо проекції точок на пряму A (показану синім кольором). Координати проекцій цих точок на пряму A такі: 2, 8, 10. Середнє значення - 6 2/3. Дисперсія (2-6 2/3) + (8-6 2/3) + (10-6 2/3) = 34 2/3 .
Тепер розглянемо пряму B (показану зеленим кольором). Координати точок – 2, 3, 7; середнє значення - 4, дисперсія - 14. Отже, на пряму B відбивається менша частка дисперсії, ніж пряму A.
Яка ця частка? Оскільки прямі A та B ортогональні (перпендикулярні), частки загальної дисперсії, що проеціюються на A та B, не перетинаються. Отже, загальну дисперсію розташування цікавих для нас точок можна обчислити як суму цих двох доданків: 34 2 / 3 +14 = 48 2 / 3 . У цьому пряму A проектується 71,2% загальної дисперсії, але в пряму B - 28,8%.
А як визначити, на яку пряму вплине максимальна частка дисперсії? Ця пряма буде відповідати лінії регресії для цікавих для нас точок, яка позначена як C (червоний колір). На цю пряму позначиться 77,2% загальної дисперсії, і це максимально можливе значення при даному розташуванні точок. Таку пряму, яку проектується максимальна частка загальної дисперсії, називають першою головною компонентою.
А на яку пряму відобразити 22,8% загальної дисперсії, що залишилися? На пряму, перпендикулярну першій головній компоненті. Ця пряма теж буде головною компонентою, адже на неї відіб'ється максимально можлива частка дисперсії (звісно, без урахування тієї, що позначилася на першій головній компоненті). Таким чином, це - друга головна компонента.
Обчисливши ці основні компоненти з допомогою Statistica (діалог ми опишемо трохи згодом), ми отримаємо картину, показану на рис. 9.1.2. Координати точок на основних компонентах показуються в стандартних відхиленнях.

Мал. 9.1.2. Розташування трьох точок, показаних на рис. 9.1.1, на площині двох основних компонентів. Чому ці точки розташовуються одна щодо одної інакше, ніж рис. 9.1.1?
На рис. 9.1.2 взаєморозташування точок виявляється зміненим. Щоб надалі правильно інтерпретувати подібні картинки, слід розглянути причини відмінностей розташування точок на рис. 9.1.1 та 9.1.2 докладніше. Точка 1 в обох випадках знаходиться правіше (має велику координату за першою ознакою та першою головною компонентою), ніж точка 2. Але, чомусь, точка 3 на вихідному розташуванні знаходиться нижче двох інших точок (має найменше значення ознаки 2), і вище двох інших точок на площині головних компонентів (має велику координату по другій компоненті). Це пов'язано з тим, що метод головних компонент оптимізує саме дисперсію вихідних даних, що проектуються на осі, що вибираються ним. Якщо головна компонента корелюється з якоюсь вихідною віссю, компонента і вісь можуть бути спрямовані в одну сторону (мати позитивну кореляцію) або в протилежні сторони (мати негативні кореляції). Обидва ці варіанти рівнозначні. Алгоритм методу основних компонентів може «перевернути» чи «перевернути» будь-яку площину; ніяких висновків на підставі цього робити не слід.
Проте крапки на рис. 9.1.2 не просто «перевернуті» в порівнянні з їх взаєморозташуванням на рис. 9.1.1; певним чином змінилося та їх взаєморозташування. Відмінності між точками по другому головному компоненті здаються посиленими. 22,76% загальної дисперсії, що припадають на другу компоненту, «розсунули» точки на таку саму дистанцію, як і 77,24% дисперсії, що припадають на першу головну компоненту.
Щоб розташування точок на площині головних компонентів відповідало їх дійсному розташуванню, цю площину слід би спотворити. На рис. 9.1.3. показано два концентричні кола; їх радіуси співвідносяться як частки дисперсій, що відображаються першою та другою головними компонентами. Картинка, що відповідає рис. 9.1.2, спотворена так, щоб середньоквадратичне відхилення по першій головній компоненті відповідало більшому колу, а по другій - меншому.

Мал. 9.1.3. Ми врахували, що на першу головну компоненту доводиться б обільша частка дисперсії, ніж другу. Для цього ми спотворили рис. 9.1.2, підігнавши його під два концентричні кола, радіуси яких співвідносяться, як частки дисперсій, що припадають на головні компоненти. Але розташування точок однаково відповідає вихідному, показаному на рис. 9.1.1!
А чому взаємне розташування точок на рис. 9.1.3 не відповідає такому на рис. 9.1.1? На вихідному малюнку, рис. 9.1 точки розташовані відповідно до своїх координат, а не відповідно до частин дисперсії, що припадають на кожну вісь. Відстань 1 одиницю за першою ознакою (по осі абсцис) на рис. 9.1.1 припадає менша частка дисперсії точок цієї осі, ніж відстані в 1 одиницю за другою ознакою (по осі ординат). На рис 9.1.1 відстані між точками визначаються саме тими одиницями, у яких вимірюються ознаки, якими вони описані.
Дещо ускладнимо завдання. У табл. 9.1.1 показані координати 10 точок у 10-мірному просторі. Перші три точки і перші два виміри – це той приклад, який ми щойно розглядали.
Таблиця 9.1.1. Координати точок для подальшого аналізу
|
Координати |
||||||||||
У навчальних цілях спочатку розглянемо лише частину даних із табл. 9.1.1. На рис. 9.1.4 бачимо положення десяти точок на площині перших двох ознак. Зверніть увагу, що перша головна компонента (пряма C) пройшла дещо інакше, ніж у попередньому випадку. Нічого дивного: на її становище впливають усі точки, що розглядаються.

Мал. 9.1.4. Ми збільшили кількість точок. Перша головна компонента проходить вже трохи інакше, адже на неї вплинули додані точки.
На рис. 9.1.5 показано положення розглянутих нами 10 точок на площині двох перших компонентів. Зверніть увагу: все змінилося, не тільки частка дисперсії, що припадає на кожну головну компоненту, а й положення перших трьох точок!

Мал. 9.1.5. Ординація в площині перших основних компонентів 10 точок, охарактеризованих у табл. 9.1.1. Розглядалися лише значення двох перших ознак, останні 8 шпальт табл. 9.1.1 не використовувалися
Загалом, це природно: якщо основні компоненти розташовані інакше, то змінилося і взаєморозташування точок.
Труднощі в зіставленні розташування точок на площині основних компонентів і на вихідній площині значень їх ознак можуть викликати здивування: навіщо використовувати такий метод, що важко інтерпретується? Відповідь проста. У тому випадку, якщо об'єкти, що порівнюються, описані всього за двома ознаками, цілком можна використовувати їх ординацію за цими, вихідними ознаками. Всі переваги методу основних компонентів виявляються у разі багатовимірних даних. Метод головних компонент у разі виявляється ефективним способом зниження розмірності даних.
9.2. Перехід до початкових даних з великою кількістю вимірювань
Розглянемо складніший випадок: проаналізуємо дані, подані в табл. 9.1.1 за всіма десятьма ознаками. На рис. 9.2.1 показано, як викликається вікно цікавого для нас методу.

Мал. 9.2.1. Запуск методу основних компонентів
Нас цікавитиме лише вибір ознак для аналізу, хоча діалог Statistica дозволить набагато тонше налаштувати (рис. 9.2.2).

Мал. 9.2.2. Вибір змінних для аналізу
Після виконання аналізу з'являється вікно його результатів із кількома вкладками (рис. 9.2.3). Усі основні вікна доступні з першої вкладки.

Мал. 9.2.3. Перша вкладка діалогу результатів аналізу основних компонентів
Можна побачити, що аналіз виділив 9 основних компонентів, причому описав з допомогою 100% дисперсії, відбитої у 10 початкових ознаках. Це означає, що одна ознака була зайвою, надмірною.
Почнемо переглядати результати з кнопки Plot case factor voordinates, 2D: вона покаже розташування точок на площині, заданої двома головними компонентами. Натиснувши цю кнопку, ми потрапимо у діалог, де треба буде вказати, які ми використовуватимемо компоненти; природно починати аналіз із першої та другої компонент. Результат – на рис. 9.2.4.

Мал. 9.2.4. Ординація об'єктів, що розглядаються на площині двох перших головних компонент
Положення точок змінилося, і це природно: до аналізу залучені нові ознаки. На рис. 9.2.4 відображено понад 65% усієї різноманітності в положенні точок одна щодо одної, і це вже нетривіальний результат. Наприклад, повернувшись до табл. 9.1.1 можна переконатися в тому, що точки 4 і 7, а також 8 і 10 дійсно досить близькі один до одного. Втім, відмінності між ними можуть стосуватися інших головних компонентів, не показаних на малюнку: на них, все-таки, теж припадає третина мінливості, що залишилася.
До речі, при аналізі розміщення точок на площині основних компонентів може виникнути необхідність проаналізувати відстані між ними. Найпростіше отримати матрицю дистанцій між точками із використанням модуля для кластерного аналізу.
Як виділені основні компоненти пов'язані з вихідними ознаками? Це можна з'ясувати, натиснувши кнопку (рис. 9.2.3) Plot var. factor coordinates, 2D. Результат – на рис. 9.2.5.

Мал. 9.2.5. Проекції вихідних ознак на площину двох перших головних компонентів
Ми дивимося на площину двох основних компонентів «згори». Вихідні ознаки, які ніяк не пов'язані з головними компонентами, будуть перпендикулярні (або майже перпендикулярні) їм і позначаться короткими відрізками, що закінчуються поблизу початку координат. Так, найменше з двома першими головними компонентами пов'язаний ознака № 6 (хоча він демонструє певну позитивну кореляцію з першою компонентою). Відрізки, що відповідають тим ознакам, які повністю відіб'ються на площині основних компонентів, будуть закінчуватися на охоплює центр малюнка кола одиничного радіусу.
Наприклад, можна побачити, що на першу головну компоненту найсильніше вплинули ознаки 10 (пов'язаний позитивною кореляцією), а також 7 і 8 (пов'язані негативною кореляцією). Щоб розглянути структуру таких кореляцій докладніше, можна натиснути кнопку Factor coordinates of variables та отримати таблицю, показану на рис. 9.2.6.

Мал. 9.2.6. Кореляції між вихідними ознаками та виділеними головними компонентами (Factors)
Кнопка Eigenvalues виводить величини, які називаються своїми значеннями основних компонент. У верхній частині вікна, показаного на рис. 9.2.3 виведені такі значення для декількох перших компонент; кнопка Scree plot показує їх у зручній для сприйняття формі (рис. 9.2.7).

Мал. 9.2.7. Власні значення виділених головних компонент та частки відбитої ними загальної дисперсії
Для початку треба зрозуміти, що саме показує значення значенняієї. Це - міра дисперсії, що відбилася на головну компоненту, виміряна в кількості дисперсії, що припадала на кожну ознаку початкових даних. Якщо значення першої головної компоненти дорівнює 3,4, це означає, що на неї відображається більше дисперсії, ніж на три ознаки з початкового набору. Власні величини лінійно пов'язані з часткою дисперсії, що припадає на головну компоненту, єдине, що сума власних значень дорівнює кількості вихідних ознак, а сума часткою дисперсії дорівнює 100%.
А що означає, що інформацію про мінливість за 10 ознаками вдалося відобразити у 9 основних компонентах? Що один із початкових ознак був надлишковим, не додавав жодної нової інформації. Так і було; на рис. 9.2.8 показано, як було згенеровано набір точок, відображений у табл. 9.1.1.
Головні компоненти
5.1 Методи множинної регресії та канонічної кореляції припускають розбиття наявного набору ознак на дві частини. Однак, далеко не завжди таке розбиття може бути об'єктивно добре обґрунтованим, у зв'язку з чим виникає потреба в таких підходах до аналізу взаємозв'язків показників, які б передбачали розгляд вектора ознак як єдиного цілого. Зрозуміло, при реалізації подібних підходів у цій батареї ознак може бути виявлено певну неоднорідність, коли об'єктивно виявляться кілька змінних груп. Для ознак з однієї такої групи взаємні кореляції будуть набагато вищими порівняно з поєднаннями показників із різних груп. Однак, це угруповання спиратиметься на результати об'єктивного аналізу даних, а не на апріорні довільні міркування дослідника.
5.2 При вивченні кореляційних зв'язків усередині деякого єдиного набору m ознак
X"= X 1 X 2 X 3 ... X m
можна скористатися тим самим способом, який застосовувався в множинному регресійному аналізі та методі канонічних кореляцій - отриманням нових змінних, варіація яких повно відображає існування багатовимірних кореляцій.
Метою розгляду внутрішньогрупових зв'язків єдиного набору ознак є визначення та наочне уявлення об'єктивно існуючих основних напрямів співвідносної варіації цих змінних. Тому для цих цілей можна ввести деякі нові змінні Y i , що знаходяться як лінійні комбінації вихідного набору ознак X
Y 1 = b 1 "X= b 11 X 1 + b 12 X 2 + b 13 X 3 + ... + b 1m X m
Y 2 = b 2 "X= b 21 X 1 + b 22 X 2 + b 23 X 3 + ... + b 2m X m
Y 3 = b 3 "X= b 31 X 1 + b 32 X 2 + b 33 X 3 + ... + b 3m X m (5.1)
... ... ... ... ... ... ...
Y m = b m "X= b m1 X 1 + b m2 X 2 + b m3 X 3 + ... + b m m X m
і які мають ряд бажаних властивостей. Нехай для визначеності число нових ознак дорівнює кількості вихідних показників (m).
Однією з таких бажаних оптимальних властивостей може бути взаємна некорелеваність нових змінних, тобто діагональний вигляд їхньої коваріаційної матриці
S y1 2 0 0 ... 0
0 s y2 2 0 ... 0
S y= 0 0 s y3 2 ... 0 (5.2)
... ... ... ... ...
0 0 0 … s ym 2
де s yi 2 - дисперсія i-ї нової ознаки Y i . Некорелеваність нових змінних крім своєї очевидної зручності має важливу властивість - кожна нова ознака Y i буде враховувати тільки свою незалежну частину інформації про мінливість та корелювання вихідних показників X.
Другою необхідною властивістю нових ознак є впорядкований облік варіації вихідних показників. Так, нехай перша нова змінна Y 1 враховуватиме максимальну частку сумарної варіації ознак X. Це, як ми пізніше побачимо, рівносильне вимогі того, щоб Y 1 мала максимально можливу дисперсію s y1 2 . З урахуванням рівності (1.17) ця умова може бути записана у вигляді
s y1 2 = b 1 "Sb 1= max (5.3)
де S- коваріаційна матриця вихідних ознак X, b 1- Вектор, що включає коефіцієнти b 11 , b 12 , b 13 , ..., b 1m за допомогою яких, за значеннями X 1 , X 2 , X 3 , ..., X m можна отримати значення Y 1 .
Нехай друга нова змінна Y 2 описує максимальну частину того компонента сумарної варіації, який залишився після врахування найбільшої його частки мінливості першої нової ознаки Y 1 . Для цього необхідно виконання умови
s y2 2 = b 2 "Sb 2= max (5.4)
при нульовому зв'язку Y 1 з Y 2 (тобто r y1y2 = 0) і при s y1 2 > s y2 2 .
Аналогічним чином, третя нова ознака Y 3 повинна описувати третю за ступенем важливості частину варіації вихідних ознак, для чого його дисперсія повинна бути також максимальною
s y3 2 = b 3 "Sb 3= max (5.5)
за умов, що Y 3 нескорелювання з першими двома новими ознаками Y 1 і Y 2 (тобто r y1y3 = 0, r y2y3 = 0) і s y1 2 > s y2 > s y3 2 .
Таким чином, для дисперсій усіх нових змінних характерна впорядкованість за величиною
s y1 2 > s y2 2 > s y3 2 > ... > s y m 2 . (5.6)
5.3 Вектори із формули (5.1) b 1 , b 2 , b 3 , ..., b m , за допомогою яких повинен здійснюватися перехід до нових змінних Y i , можуть бути записані у вигляді матриці
B = b 1 b 2 b 3 ... b m. (5.7)
Перехід від набору вихідних ознак Xдо набору нових змінних Yможе бути представлений у вигляді матричної формули
Y = B" X , (5.8)
а отримання коваріаційної матриці нових ознак і досягнення умови (5.2) некорелювання нових змінних відповідно до формули (1.19) може бути подане у вигляді
B"SB= S y , (5.9)
де коваріаційна матриця нових змінних S yв силу їх некорелювання має діагональну форму. З теорії матриць (розділ А.25Додатки А) відомо, що, отримавши для деякої симетричної матриці Aвласні вектори u iі числа l i і обра-
кликавши з них матриці Uі L, можна відповідно до формули (А.31) отримати результат
U"AU= L ,
де L- діагональна матриця, що включає власні числа симетричної матриці A. Неважко бачити, що остання рівність повністю збігається з формулою (5.9). Тому можна зробити наступний висновок. Бажані властивості нових змінних Yможна забезпечити, якщо вектори b 1 , b 2 , b 3 , ..., b m , за допомогою яких повинен здійснюватися перехід до цих змінних, будуть власними векторами матриці ковараційної вихідних ознак S. Тоді дисперсії нових ознак s yi 2 виявляться власними числами
s y1 2 = l 1 , s y2 2 = l 2 , s y3 2 = l 3 , ... , s ym 2 = l m (5.10)
Нові змінні, перехід яких за формулами (5.1) і (5.8) здійснюється з допомогою власних векторів ковариационной матриці вихідних ознак, називаються головними компонентами. У зв'язку з тим, що кількість власних векторів ковариационной матриці у випадку дорівнює m - числу вихідних ознак цієї матриці, кількість основних компонент також дорівнює m.
Відповідно до теорії матриць для знаходження власних чисел і векторів матриці кваріації слід вирішити рівняння
(S- l i I)b i = 0 . (5.11)
Це рівняння має рішення, якщо виконується умова рівності нулю визначника
½ S- l i I½ = 0 . (5.12)
Ця умова по суті також виявляється рівнянням, корінням якого є всі власні числа l 1 , l 2 , l 3 ... l m коваріаційної матриці одночасно збігаються з дисперсіями головних компонент. Після отримання цих чисел для кожного i-го з них за рівнянням (5.11) можна отримати відповідний власний вектор b i. На практиці для обчислення власних чисел та векторів використовуються спеціальні ітераційні процедури (Додаток В).
Усі власні вектори можна записати як матриці B, яка буде ортонормованою матрицею, так що (розділ А.24Додатки А) для неї виконується
B"B = BB" = I . (5.13)
Останнє означає, що для будь-якої пари власних векторів справедливо b i "b j= 0, а для будь-якого такого вектора дотримується рівність b i "b i = 1.
5.4 Проілюструємо отримання основних компонентів для найпростішого випадку двох вихідних ознак X 1 і X 2 . Коваріаційна матриця для цього набору дорівнює
де s 1 і s 2 - середні квадратичні відхилення ознак X 1 і X 2 а r - коефіцієнт кореляції між ними. Тоді умову (5.12) можна записати у вигляді
S 1 2 - l i rs 1 s 2
rs 1 s 2 s 2 2 - l i

Малюнок 5.1.Геометричний зміст основних компонентів
Розкриваючи визначник, можна отримати рівняння
l 2 - l(s 1 2 + s 2 2) + s 1 2 s 2 2 (1 - r 2) = 0 ,
вирішуючи яке, можна отримати два корені l1 і l2. Рівняння (5.11) може бути записано у вигляді
s 1 2 - l i r s 1 s 2 b i1 = 0
r s 1 s 2 s 2 2 - l i b i2 0
Підставляючи це рівняння l 1 , отримаємо лінійну систему
(s 1 2 - l 1) b 11 + rs 1 s 2 b 12 = 0
rs 1 s 2 b 11 + (s 2 2 - l 1)b 12 = 0
рішенням якої є елементи першого власного вектора b11 і b12. Після аналогічної підстановки другого кореня l 2 знайдемо елементи другого власного вектора b 21 і 22 .
5.5 З'ясуємо геометричний зміст основних компонентів. Наочно це можна зробити лише найпростішого випадку двох ознак X 1 і X 2 . Нехай їм характерно двовимірне нормальне розподіл із позитивним значенням коефіцієнта кореляції. Якщо всі індивідуальні спостереження нанести на площину, освічену осями ознак, то відповідні точки розташуються всередині деякого кореляційного еліпса (рис.5.1). Нові ознаки Y 1 та Y 2 також можуть бути зображені на цій же площині у вигляді нових осей. За змістом методу першої головної компоненти Y 1 , що враховує максимально можливу сумарну дисперсію ознак X 1 і X 2 , повинен досягатися максимум її дисперсії. Це означає, що для Y 1 слід знайти та-
ку вісь, щоб ширина розподілу її значень була б найбільшою. Очевидно, що це буде досягатися, якщо ця вісь збігатиметься з найбільшою віссю кореляційного еліпса. Справді, якщо ми спроектуємо всі відповідні індивідуальним спостереженням точки на цю координату, то отримаємо нормальний розподіл із максимально можливим розмахом та найбільшою дисперсією. Це буде розподіл індивідуальних значень першої головної компоненти Y1.
Вісь, що відповідає другій головній компоненті Y 2 повинна бути проведена перпендикулярно до першої осі, так як це випливає з умови некорелюваності головних компонент. Справді, у разі ми отримаємо нову систему координат з осями Y 1 і Y 2 , які збігаються у напрямі з осями кореляційного еліпса. Можна бачити, що кореляційний еліпс при його розгляді в новій системі координат демонструє некорельованість індивідуальних значень Y 1 і Y 2 тоді як для величин вихідних ознак X 1 і X 2 кореляція спостерігалася.
Перехід від осей, пов'язаних з вихідними ознаками X 1 і X 2 до нової системи координат, орієнтованої на головні компоненти Y 1 і Y 2 , рівносильний повороту старих осей на деякий кут j. Його величина може бути знайдена за формулою
Tg 2j = . (5.14)
Перехід від значень ознак X 1 та X 2 до головних компонентів може бути здійснений відповідно до результатів аналітичної геометрії у вигляді
Y 1 = X 1 cos j + X 2 sin j
Y 2 = - X 1 sin j + X 2 cos j.
Цей же результат можна записати у матричному вигляді
Y 1 = cos j sin j X 1 і Y 2 = -sin j cos j X 1 ,
який точно відповідає перетворенню Y 1 = b 1 "Xта Y 2 = b 2 "X. Іншими словами,
= B" . (5.15)
Таким чином, матриця власних векторів може трактуватися як включає тригонометричні функції кута повороту, який слід здійснити для переходу від системи координат, пов'язаної з вихідними ознаками, до нових осей, що спираються на головні компоненти.
Якщо ми маємо m вихідних ознак X 1 , X 2 , X 3 , ..., X m , то спостереження, що складають аналізовану вибірку, розташуються всередині деякого m-мірного кореляційного еліпсоїда. Тоді вісь першої головної компоненти збігається у напрямку найбільшої віссю цього еліпсоїда, вісь другої головної компоненти - з другою віссю цього еліпсоїда і т.д. Перехід від початкової системи координат, пов'язаної з осями ознак X 1 , X 2 , X 3 , ..., X m до нових осей головних компонент виявиться рівносильним здійсненню кількох поворотів старих осей на кути j 1 , j 2 , j 3 , . ., а матриця переходу Bвід набору Xдо системи основних компонент Y, Що складається з власних вік-
торов ковариационной матриці, включає тригонометричні функції кутів нових координатних осей зі старими осями вихідних ознак.
5.6 Відповідно до властивостей власних чисел і векторів сліди коваріаційних матриць вихідних ознак і головних компонент - рівні. Іншими словами
tr S= tr S y = tr L (5.16)
s 11 + s 22 + ... + s mm = l 1 + l 2 + ... + l m ,
тобто. сума власних чисел ковариационной матриці дорівнює сумі дисперсій всіх вихідних ознак. Тому можна говорити про деяку сумарну величину дисперсії вихідних ознак рівної tr S, та враховується системою власних чисел.
Та обставина, що перша головна компонента має максимальну дисперсію, рівну l 1 автоматично означає, що вона описує і максимальну частку сумарної варіації вихідних ознак tr S. Аналогічно, друга головна компонента має другу за величиною дисперсію l 2 що відповідає другий за величиною враховується частці сумарної варіації вихідних ознак і т.д.
Для кожної головної компоненти можна визначити частку сумарної величини мінливості вихідних ознак, яку вона описує
5.7 Вочевидь, уявлення про сумарної варіації набору вихідних ознак X 1 , X 2 , X 3 , ... S, має сенс лише тому випадку, коли всі ці ознаки виміряні в однакових одиницях. В іншому випадку доведеться складати дисперсії, різних ознак, одні з яких будуть виражені у квадратах міліметрів, інші – у квадратах кілограмів, треті – у квадратах радіан чи градусів тощо. Ці труднощі легко уникнути, якщо від іменованих значень ознак X ij перейти до їх нормованих величин z ij = (X ij - Mi). Нормовані ознаки z мають нульові середні, поодинокі дисперсії і пов'язані з будь-якими одиницями виміру. Коваріаційна матриця вихідних ознак Sперетвориться на кореляційну матрицю R.
Все сказане про головні компоненти, що знаходяться для коварійної матриці, залишається справедливим і для матриці R. Тут так само можна, спираючись на власні вектори кореляційної матриці b 1 , b 2 , b 3 , ..., b m перейти від вихідних ознак z i до головних компонентів y 1 , y 2 , y 3 , ..., y m
y 1 = b 1 "z
y 2 = b 2 "z
y 3 = b 3 "z
y m = b m "z .
Це перетворення можна також записати в компактному вигляді
y = B"z ,

Малюнок 5.2. Геометричний зміст головних компонент для двох нормованих ознак z1 і z2
де y- Вектор значень головних компонент, B- матриця, що включає власні вектори, z- Вектор вихідних нормованих ознак. Справедливим виявляється і рівність
B"RB= ... ... … , (5.18)
де l 1 l 2 l 3 ... l m - власні числа кореляційної матриці.
Результати, що виходять при аналізі кореляційної матриці, відрізняються від аналогічних результатів для коваріаційної матриці. По-перше, тепер можна розглядати ознаки, виміряні у різних одиницях. По-друге, власні вектори та числа, знайдені для матриць Rі S, також різні. По-третє, головні компоненти, визначені кореляційної матриці і які спираються на нормовані значення ознак z, виявляються центрованими - тобто. мають нульові середні величини.
На жаль, визначивши власні вектори та числа для кореляційної матриці, перейти від них до аналогічних векторів та числа коваріаційної матриці - неможливо. Насправді зазвичай застосовуються основні компоненти, що спираються на кореляційну матрицю, як універсальні.
5.8 Розглянемо геометричний зміст основних компонентів, визначених за кореляційною матрицею. Наочним тут виявляється випадок двох ознак z1 і z2. Система координат, що з цими нормованими ознаками, має нульову точку, розміщену у центрі графіка (рис.5.2). Центральна точка кореляційного еліпса,
включає всі індивідуальні спостереження, збігається з центром системи координат. Очевидно, що вісь першої головної компоненти, що має максимальну варіацію, збігається з найбільшою віссю кореляційного еліпса, а координата другої головної компоненти буде зорієнтована другої осі цього еліпса.
Перехід від системи координат, пов'язаної з вихідними ознаками z 1 і z 2 до нових осей головних компонент, рівносильний повороту перших осей на деякий кут j. Дисперсії нормованих ознак дорівнюють 1 і за формулою (5.14) можна знайти величину кута повороту j рівну 45 o . Тоді матриця власних векторів, яку можна визначити через тригонометричні функції цього кута за формулою (5.15), дорівнюватиме
Cos j sin j 1 1 1
B" = = .
Sin j cos j (2) 1/2 -1 1
Значення власних чисел для двовимірного випадку також легко знайти. Умова (5.12) виявиться виду
що відповідає рівнянню
l 2 - 2l + 1 - r 2 = 0
яке має два корені
l 1 = 1 + r (5.19)
Таким чином, головні компоненти кореляційної матриці для двох нормованих ознак можуть бути знайдені за дуже простими формулами
Y 1 = (z 1 + z 2) (5.20)
Y 2 = (z 1 - z 2)
Їхні середні арифметичні величини дорівнюють нулю, а середні квадратичні відхилення мають значення
s y1 = (l 1) 1/2 = (1 + r) 1/2
s y2 = (l 2) 1/2 = (1 - r) 1/2
5.9 Відповідно до властивостей власних чисел та векторів сліди кореляційної матриці вихідних ознак та матриці власних чисел – рівні. Сумарна варіація m нормованих ознак дорівнює m. Іншими словами
tr R= m = tr L (5.21)
l 1 + l 2 + l 3 + ... + l m = m.
Тоді частка сумарної варіації вихідних ознак, що описується першою головною компонентою дорівнює
Можна також запровадити поняття P cn - частки сумарної варіації вихідних ознак, що описується першими n головними компонентами,
n l 1 + l 2 + ... + l n
P cn = S P i =. (5.23)
Та обставина, що для власних чисел спостерігається впорядкованість виду l 1 > l 2 > > l 3 > ... > l m означає, що аналогічні співвідношення будуть властиві і часткам, що описується головними компонентами варіації
P 1 > P 2 > P 3 > ... > P m. (5.24)
Властивість (5.24) тягне у себе специфічний вид залежності накопиченої частки P сn від n (рис.5.3). У разі перші три основні компоненти описують основну частину мінливості ознак. Це означає, що часто деякі перші головні компоненти можуть спільно враховувати до 80 - 90% сумарної варіації ознак, тоді як кожна наступна головна компонента буде збільшувати цю частку дуже незначно. Тоді для подальшого розгляду та інтерпретації можна використовувати лише ці небагато перших головних компонентів з упевненістю, що саме вони описують найважливіші закономірності внутрішньогрупової мінливості та корелюваності.

Малюнок 5.3.Залежність частки сумарної варіації ознак P cn описується n першими головними компонентами, від величини n. Число ознак m = 9

Малюнок 5.4. До визначення конструкції критерію відсіювання основних компонентів
ознак. Завдяки цьому кількість інформативних нових змінних, з якими слід працювати, може бути зменшена в 2 - 3 рази. Таким чином, головні компоненти мають ще одну важливу та корисну властивість - вони значно спрощують опис варіації вихідних ознак і роблять його компактнішим. Таке зменшення кількості змінних завжди бажано, але воно пов'язане з деякими спотвореннями взаємного розташування точок, що відповідають окремим спостереженням, у просторі небагатьох перших головних компонентів порівняно з m-мірним простором вихідних ознак. Ці спотворення виникають через спробу втиснути простір ознак у простір перших головних компонентів. Однак, у математичній статистиці доводиться, що з усіх методів, що дозволяють значно зменшити кількість змінних, перехід до основних компонентів призводить до найменших спотворень структури спостережень пов'язаних із цим зменшенням.
5.10 p align="justify"> Важливим питанням аналізу головних компонент є проблема визначення їх кількості для подальшого розгляду. Очевидно, що збільшення числа головних компонент підвищує накопичену частку мінливості P cn, що враховується, і наближає її до 1. Одночасно, компактність одержуваного опису зменшується. Вибір тієї кількості основних компонент, яка одночасно забезпечує і повноту і компактність опису може базуватися на різних умовах, що застосовуються на практиці. Перерахуємо найпоширеніші їх.
Перший критерій заснований на тому міркуванні, що кількість основних компонент, що враховуються, повинна забезпечувати достатню інформативну повноту опису. Інакше кажучи, аналізовані основні компоненти повинні описувати більшість сумарної мінливості вихідних ознак: до 75 - 90%. Вибір конкретного рівня накопиченої частки P cn залишається суб'єктивним і залежить як від думки дослідника, і від вирішуваного завдання.
Інший аналогічний критерій (критерій Кайзера) дозволяє включати в розгляд основні компоненти зі своїми числами більшими 1. Він заснований на тому міркуванні, що 1 - це дисперсія однієї нормованої вихідної ознаки. Поет-
му, включення до подальшого розгляду всіх головних компонент зі своїми числами великими 1 означає що ми розглядаємо ті нові змінні, які мають дисперсії щонайменше ніж в однієї вихідного ознаки. Критерій Кайзера дуже поширений і його використання закладено в багато пакетів програм статистичної обробки даних, коли потрібно задати мінімальну величину власного числа, що враховується, і за замовчуванням часто приймається значення дорівнює 1.
Дещо краще теоретично обгрунтований критерій відсіювання Кеттела. Його застосування ґрунтується на розгляді графіка, на якому нанесено значення всіх власних чисел у порядку їх зменшення (рис.5.4). Критерій Кеттела заснований на тому ефект, що нанесена на графік послідовність величин отриманих власних чисел зазвичай дає увігнуту лінію. Декілька перших власних чисел виявляють непрямолинійне зменшення свого рівня. Однак, починаючи з деякого власного числа, зменшення рівня стає приблизно прямолінійним і досить пологим. Включення основних компонентів на розгляд завершується тій із них, власне число якої починає прямолінійний пологий ділянку графіка. Так, на малюнку 5.4 у відповідність до критерію Кеттела на розгляд слід включити лише перші три основні компоненти, тому що третє власне число знаходиться на самому початку прямолінійної пологої ділянки графіка.
Критерій Кеттела ґрунтується на наступному. Якщо розглядати дані за m ознаками, штучно отримані з таблиці нормально розподілених випадкових чисел, то для них кореляції між ознаками носитимуть цілком випадковий характер і будуть близькими до 0. При знаходженні тут головних компонентів можна буде виявити поступове зменшення величини їх власних чисел, що має прямолінійну характер. Іншими словами, прямолінійне зменшення власних чисел може свідчити про відсутність у відповідній їм інформації про корелювання ознак невипадкових зв'язків.
5.11 При інтерпретації основних компонентів найчастіше застосовуються власні вектори, представлені у вигляді про навантажень - коефіцієнтів кореляції вихідних ознак з основними компонентами. Власні вектори b i, що задовольняють рівності (5.18), виходять у нормованому вигляді, так що b i "b i= 1. Це означає, що сума квадратів елементів кожного власного вектора дорівнює 1. Власні вектори, елементи яких є навантаженнями, можуть бути легко знайдені за формулою
a i= (l i) 1/2 b i . (5.25)
Іншими словами, примноженням нормованої форми власного вектора на квадратний корінь його власного числа, можна отримати набір навантажень вихідних ознак на відповідну головну компоненту. Для векторів навантажень справедливим виявляється рівність a i "a i= l i , Що означає, що сума квадратів навантажень на i-ю головну компоненту дорівнює i-му власному числу. Комп'ютерні програми зазвичай виводять власні вектори у вигляді навантажень. При необхідності отримання цих векторів у нормованому вигляді b iце можна зробити за простою формулою b i = a i/ (l i) 1/2.
5.12 Математичні властивості власних чисел та векторів такі, що відповідно до розділу А.25Додатки А вихідна кореляційна матриця Rможе бути представлена у вигляді R = BLB", що також можна записати як
R= l 1 b 1 b 1 "+ l 2 b 2 b 2 "+ l 3 b 3 b 3 "+ ... + l m b m b m " . (5.26)
Слід зазначити, що кожен із членів l i b i b i ", що відповідає i-му головному компоненту, є квадратною матрицею
L i b i1 2 l i b i1 b i2 l i b i1 b i3 … l i b i1 b im
l i b i b i "= l i b i1 b i2 l i b i2 2 l i b i2 b i3 ... l i b i2 b im. (5.27)
... ... ... ... ...
l i b i1 b im l i b i2 b im l i b i3 b im ... l i b im 2
Тут b ij - елемент i-го власного вектора j-го вихідного ознаки. Будь-який діагональний член такої матриці l i b ij 2 є деяка частка варіації j-го ознаки, що описується i-ю головною компонентою. Тоді дисперсія будь-якої j-ї ознаки може бути представлена у вигляді
1 = l 1 b 1j 2 + l 2 b 2j 2 + l 3 b 3j 2 + ... + l m b mj 2 , (5.28)
що означає її розкладання по вкладах, що залежать від усіх основних компонентів.
Аналогічно, будь-який позадіагональний член l i b ij b ik матриці (5.27) є деякою частиною коефіцієнта кореляції r jk j-го та k-го ознак, що враховується i-ю головною компонентою. Тоді можна виписати розкладання цього коефіцієнта у вигляді суми
r jk = l 1 b 1j b 1k + l 2 b 2j b 2k + ... + l m b mj b mk , (5.29)
вкладів у нього всіх m основних компонентів.
Таким чином, з формул (5.28) та (5.29) можна наочно бачити, що кожна головна компонента описує певну частину дисперсії кожної вихідної ознаки та коефіцієнта кореляції кожного їх поєднання.
З урахуванням того, що елементи нормованої форми власних векторів b ij пов'язані з навантаженнями a ij простим співвідношенням (5.25), розкладання (5.26) може бути виписано і через власні вектори навантажень R = AA", що також можна уявити як
R = a 1 a 1" + a 2 a 2" + a 3 a 3" + ... + a m a m" , (5.30)
тобто. як суму вкладів кожної з m основних компонентів. Кожен із цих вкладів a i a i "можна записати у вигляді матриці
A i1 2 a i1 a i2 a i1 a i3 ... a i1 a im
a i1 a i2 a i2 2 a i2 a i3 ... a i2 a im
a i a i "= a i1 a i3 a i2 a i3 a i3 2 ... a i3 a im , (5.31)
... ... ... ... ...
a i1 a im a i2 a im a i3 a im ... a im 2
на діагоналях якої розміщені a ij 2 - вклади в дисперсію j-ї вихідної ознаки, а позадіагональні елементи a ij a ik - є аналогічні вклади в коефіцієнт кореляції r jk j-го та k-го ознак.